私服魔域_新开魔域SF- 玩服找好服就上私服外挂魔域发布网
魔域私服发布网主要发布魔域私服最新版本开服资讯,魔域私服外挂为超666666万名玩家提供了魔域SF发布网站游戏体验,这里提供免费和好玩私服魔域等多种选择。



- 深入探究魔域私服发布网:特性、更新及潜在风险全解析2025-11-05
- 魔域sf发布网:整合私服资源,风险并存,类型多样玩法丰富2025-11-05
- 魔域私服外挂的危害:破坏游戏平衡与影响玩家体验的深度解析2025-11-05
- 魔域私服游戏体验深度解析:玩家数量、流畅度与快速升级的独特魅力2025-11-05
- 魔域sf独特魅力引玩家,技术成熟玩法多版本迭代2025-11-05
- 魔域私服外挂严重破坏游戏公平性及运营秩序,详细阐述相关问题2025-11-05
- 深度剖析:因玩家追求自由兴起的私服魔域独特现象2025-11-05
- 新开魔域私服怎么找、新手如何注册及升级技巧全分享
新开的魔域私服能够给玩家带来全新的游戏体验,然而要找到合适的新开服并且顺利融入其中并非易事。以下是关于新开魔域私服的一些内容分享。寻找新服若想加入新开的魔域私服,需要通过专门的论坛去寻找新开服的信息。
- 魔域发布网:新服信息、游戏策略与丰富资源一站式获取平台
魔域发布网是众多魔域玩家获取游戏资源、交流心得的关键场所。该平台在魔域游戏生态中扮演着至关重要的角色。平台功能魔域发布网的功能相当丰富。它能展示新开魔域游戏服务器的信息,让玩家能及时掌握新服情况,不错
- 魔域私服外挂严重破坏游戏体验及公平性,致玩家流失
在魔域私服这款游戏当中,外挂问题对游戏体验以及公平性造成了严重影响。它破坏了游戏的正常环境,还损害了玩家和开发者的利益。接下来,一同去看看魔域私服外挂的相关情况。游戏公平性破坏外挂使用者能够获取到比正
- 魔域私服(SF)版本特点与玩法解析:经典版与特色版的差异对比
魔域 sf 是魔域私服的简称。它凭借着独特的魅力,吸引了众多的玩家。与官服相比较而言,它在玩法以及道具等方面,都具有不同的特征。并且,它能够给玩家带来与官服不同的别样体验。接下来,将对魔域 sf 的各

- 魔域私服发布网:玩家必看的选择指南与风险分析
我觉得魔域私服发布网是一个网络平台,上面汇聚了很多魔域私服的信息。它给玩家们提供了各种不同的游戏选择,使得玩家能够体验到有着不同版本和玩法的魔域游戏。然而,这类平台存在着一定的风险和弊端,接下来就详细
- 魔域发布网:提供各类游戏版本信息,开启热血魔幻之旅需谨慎选择
魔域发布网是个平台。这个平台为玩家提供各类魔域游戏版本信息。在这个平台上。玩家能找到自己喜欢的版本。然后开启热血的魔幻之旅。下面为你详细介绍。平台选择市场上魔域发布网数量不少,选择时得慎重。有这样一些

- 全面解析魔域sf版:独特玩法与复杂经济投入深度剖析
魔域sf版是魔域官方服务器的一个私人版本,它虽带来了与众不同的游戏感受,然而同时也带来了一系列的复杂问题。接下来,我将从多个角度为大家逐一深入解析。独特玩法魔域sf的一大亮点是其独特的游戏方式。与官方
- 魔域发布网:新服信息、游戏策略与丰富资源一站式获取平台
魔域发布网是众多魔域玩家获取游戏资源、交流心得的关键场所。该平台在魔域游戏生态中扮演着至关重要的角色。平台功能魔域发布网的功能相当丰富。它能展示新开魔域游戏服务器的信息,让玩家能及时掌握新服情况,不错
- 重温经典私服魔域,畅享多样玩法与浓厚社交体验11-05
- 魔域私服揭秘:独特玩法与社交互动及潜在风险全解析11-05
- 深入了解私服魔域:玩法特色、装备获取及游戏社群全解析11-05
- 深入探究魔域sf发布网:资源聚合与热门资讯的游戏平台11-05
- 魔域发布网:新服信息、游戏策略与丰富资源一站式获取平台11-05
- 新开魔域私服:全新地图、怪物与玩法,轻松升级体验11-05
游戏美图
- 魔域发布网:提供各类游戏版本信息,开启热血魔幻之旅需谨慎选择
魔域发布网是个平台。这个平台为玩家提供各类魔域游戏版本信息。在这个平台上。玩家能找到自己喜欢的版本。然后开启热血的魔幻之旅。下面为你详细介绍。平台选择市场上魔域发布网数量不少,选择时得慎重。有这样一些
- 魔域私服(SF)版本特点与玩法解析:经典版与特色版的差异对比11-05
- 魔域sf独特魅力引玩家,技术成熟玩法多版本迭代11-05
- 魔域发布网:汇聚丰富游戏版本与服务器选择,满足各类玩家需求11-05
- 魔域私服外挂的危害分析:破坏游戏公平性与安全风险11-05
- 魔域私服:玩法独特传承经典,玩家互动频繁版本更新有特色11-05
- 魔域私服玩法解析:军团战、家族赛与幻兽系统的独特魅力11-05
进阶攻略

- 魔域sf发布网:整合私服资源,风险并存,类型多样玩法丰富
魔域sf发布网是一个能提供魔域私服信息汇总的平台,玩家能够通过这个平台找到自己喜欢的私服,从而开启新的游戏旅程。然而,这些网站质量不一,存在着一定的风险,下面对此进行详细说明。网站作用魔域sf发布网可
- 探索魔域sf:独特玩法、轻松交流与灵活更新的全新游戏体验11-05
- 魔域私服的起源、背景与独特玩法:揭秘非官方服务器的争议与吸引力11-05
- 魔域私服外挂破坏游戏公平性及平衡性,详细分析其危害与种类11-05
- 魔域私服(SF)版本特点与玩法解析:经典版与特色版的差异对比11-05
- 魔域私服的起源与独特游戏体验:玩家为何选择私服?11-05
- 探秘魔域私服发布网:独特玩法与多样装备获取途径解析11-05
副本专题
- 魔域私服:玩法独特传承经典,玩家互动频繁版本更新有特色
魔域私服是一种特殊的游戏存在形式,它能满足部分玩家的需求,同时它还有着诸多独特之处,也存在一些问题。游戏特色魔域私服玩法独特,传承了正版魔域的一些经典元素,玩家能在其中体验热血战斗,比如军团对抗、BO
- 深入剖析魔域sf:独特玩法、特色活动与不一样的经济系统11-05
- 魔域私服外挂破坏游戏公平性及平衡性,详细分析其危害与种类11-05
- 魔域私服发布网:版本多样玩法丰富,快速找到你喜欢的私服11-05
- 魔域私服外挂严重破坏游戏公平性及正常运营,损害多方利益11-05
- 深入剖析魔域sf:独特玩法、特色活动与不一样的经济系统11-05
- 魔域私服发布网类型与选择技巧:如何找到心仪的私服11-05
截图欣赏
- 魔域私服外挂严重破坏游戏体验及公平性,致玩家流失
在魔域私服这款游戏当中,外挂问题对游戏体验以及公平性造成了严重影响。它破坏了游戏的正常环境,还损害了玩家和开发者的利益。接下来,一同去看看魔域私服外挂的相关情况。游戏公平性破坏外挂使用者能够获取到比正
- 深入探究魔域sf发布网:资源聚合与热门资讯的游戏平台11-05
- 魔域发布网:汇集多种版本资源,搭建玩家交流社区的关键平台11-05
- 魔域私服的独特吸引力与潜在风险:为何玩家如此热衷?11-05
- 探秘魔域私服发布网:独特玩法与多样装备获取途径解析11-05
- 魔域私服发布网:玩家必看的选择指南与风险分析11-05
- 游戏领域的宝库魔域发布网:汇聚多版本,功能超强大11-05
人物模拟
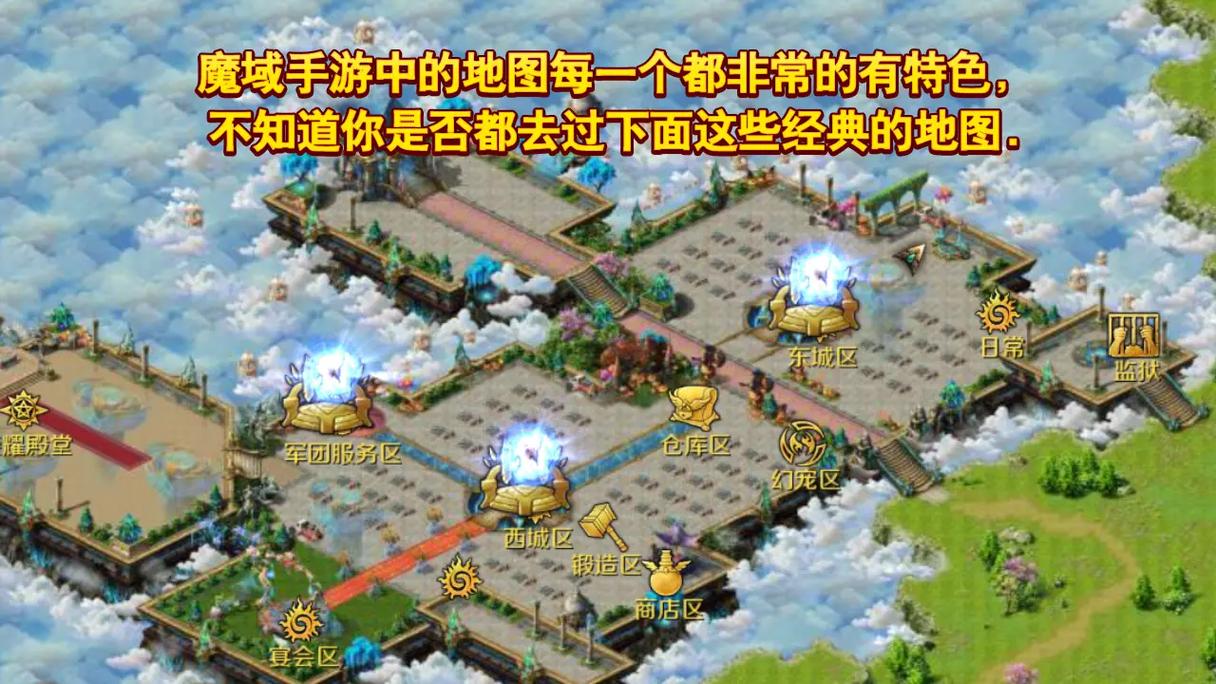
- 新开魔域私服:全新地图、怪物与玩法,轻松升级体验
新开的魔域私服能够给玩家带来崭新的游戏体验以及别样的玩法乐趣。接下来为你讲述新开魔域私服的各个方面状况。全新体验新开的魔域私服会带来和官服不一样的新鲜感,新的地图以及新的怪物会让人产生探索的欲望。它的
- 新开魔域私服:全新地图、怪物与玩法,轻松升级体验11-05
- 魔域发布网:提供多样游戏版本与安全资源的专业平台11-05
- 魔域私服外挂的危害分析:破坏游戏公平性与安全风险11-05
- 魔域私服外挂严重破坏游戏体验及公平性,致玩家流失11-05
- 新魔域私服介绍:靠谱选择与新手福利全解析11-05
- 魔域私服发布网:版本多样玩法丰富,快速找到你喜欢的私服11-05